오랑우탄의 반란
데이터 전처리 & 시각화 (3) Pandas 개념 익히기 1 본문
오늘 오랑이는 pandas를 활용한 데이터 전처리에 대해 배울 예정입니다.

지난 포스트에 이어 Pandas 의 기초 개념 몇 가지를 알아보겠습니다.
Seaborn 라이브러리의 내장데이터셋을 통해 학습하도록 하겠습니다.
- iris 데이터셋: 붓꽃의 꽃잎과 꽃받침의 길이와 너비를 포함한 데이터셋입니다.
- tips 데이터셋: 음식점에서의 팁과 관련된 정보를 담고 있는 데이터셋입니다.
- titanic 데이터셋: 타이타닉 호 승객들의 정보를 포함한 데이터셋입니다.
- flights 데이터셋: 연도별 항공편 정보를 담고 있는 데이터셋입니다.
- planets 데이터셋: 외계 행성 발견에 대한 정보를 담고 있는 데이터셋입니다.
1 데이터셋 불러오기 및 저장하기
불러오기
seaborn 라이브러리를 import 해 tips 데이터셋을 불러오고 데이터가 잘 들어가 있는지 확인합니다.
import seaborn as sns
data = sns.load_dataset('tips') # 'tips' 데이터셋 불러오기
print(data.head()) # 데이터셋 확인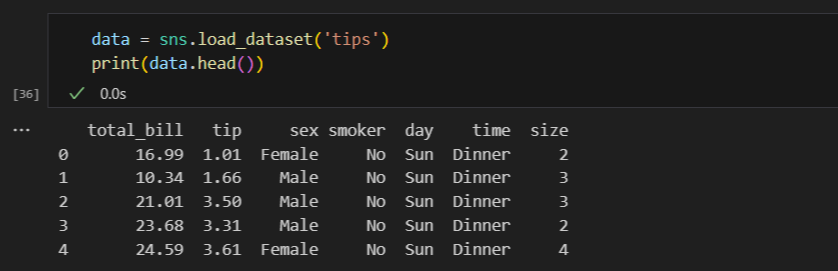
dataframe 을 위에서부터, 밑에서부터 출력해주는 함수로, 데이터셋을 불러올 때 제대로 들어있는지 간단하게 확인하는 용도입니다.
df.head(n)
df.tail(n)
저장하기
불러온 데이터를 csv, excel 등의 파일로 저장할 수 있습니다.
이때 인덱스 설정을 따로 하지 않을 경우 인덱스도 자동으로 저장되는데, 저장된 파일을 다시 불러와서 볼 때 인덱스를 보고싶지 않으면 미리 저장할 때 index = False 를 지정해주면 됩니다.
data.to_csv("temp/tips_data.csv")
data.to_excel("temp/tips_data.xlsx",index=False)
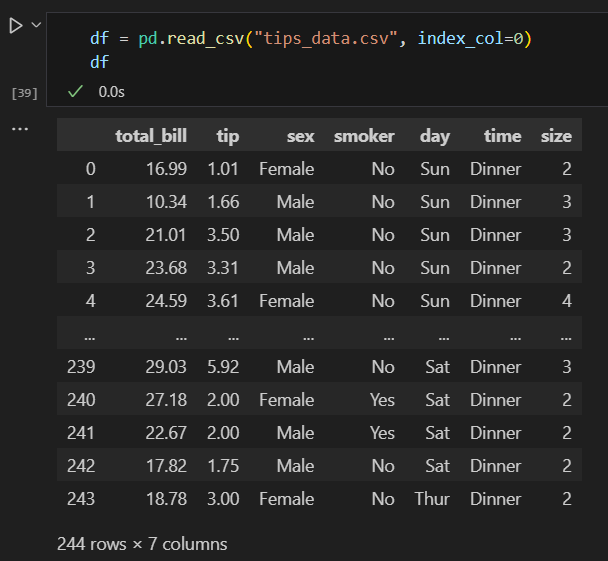
이번엔 미리 저장해둔 데이터셋을 불러와서 확인해줍니다.
저장 시 인덱스 설정을 하지 않았다면, 불러올 때 index_col = 0 으로 설정해서 보면 됩니다.
df = pd.read_csv("tips_data.csv", index_col=0)
df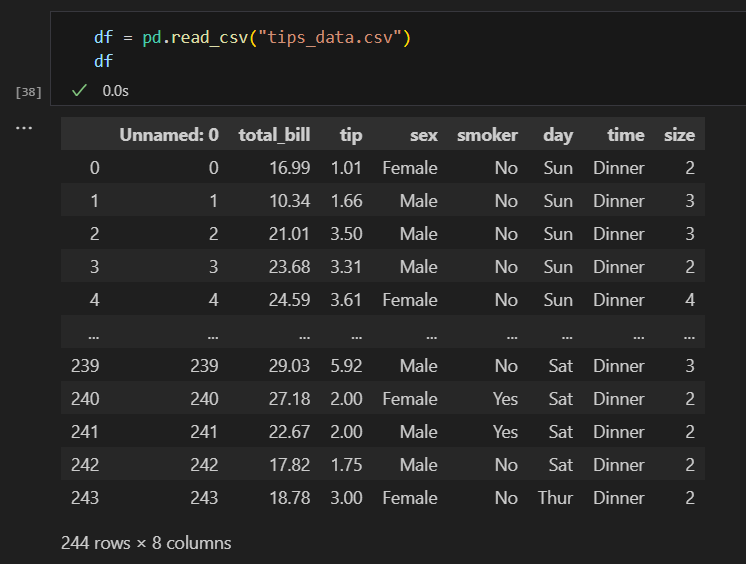
2 인덱스
인덱스에 대해 구체적으로 알아봅시다.
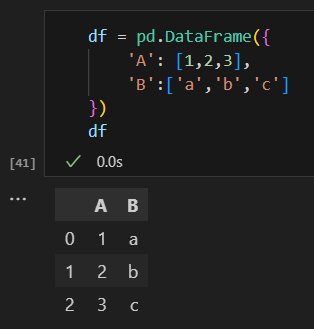
df = pd.DataFrame({
'A': [1,2,3],
'B':['a','b','c']
})
위 딕셔너리 형태의 데이터에 대해 데이터프레임으로 불러오면 자동으로 좌측에 인덱스가 붙습니다.
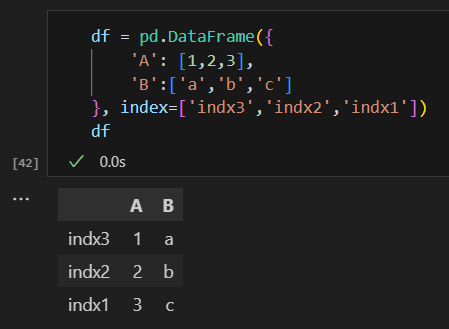
index 변수를 설정해 인덱스명을 지정할 수 있습니다.
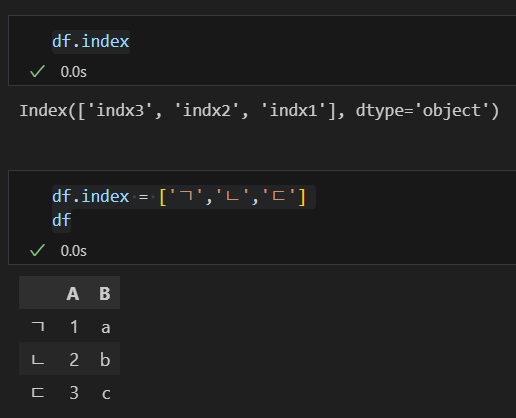
.index
인덱스명과 데이터타입을 확인할 수 있으며, 이를 변수로 사용해서 새로운 인덱스값을 부여할 수 있습니다.
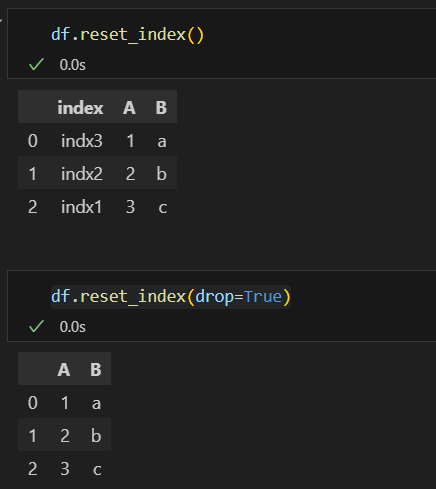
.reset_index()
위에서 함수를 사용해 설정한 인덱스명을 초기화시킬 수 있으며, drop=True 를 변수로 넣으면 인덱스명 칼럼 자체를 없애고 기본 인덱스만 남길 수 있습니다.
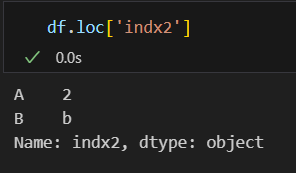
.loc[]
특정 인덱스명으로 그 인덱스 행에 해당하는 데이터와 데이터타입을 출력할 수 있습니다.
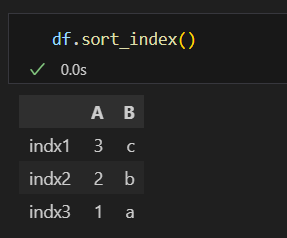
sort_index()
자세히 봤다면 앞에서 인덱스명을 거꾸로 설정했는데, 인덱스명을 오름차순으로 정렬해 데이터 위치도 함께 정렬됩니다.
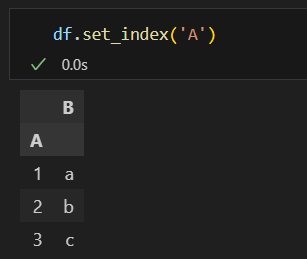
.set_index()
칼럼명을 변수로 받으며 해당 칼럼을 새로 인덱스로 지정해줍니다.
3 칼럼
칼럼에 대해 알아봅시다.
아래와 같이 딕셔너리 형태의 데이터셋을 만들어주고 데이터프레임으로 변환하면 표 형식으로 볼 수 있습니다.
data = {
'name': ['Alice','Bob','Charlie'],
'age': [25,30,35],
'gender':['female','male','male']
}
df = pd.DataFrame(data)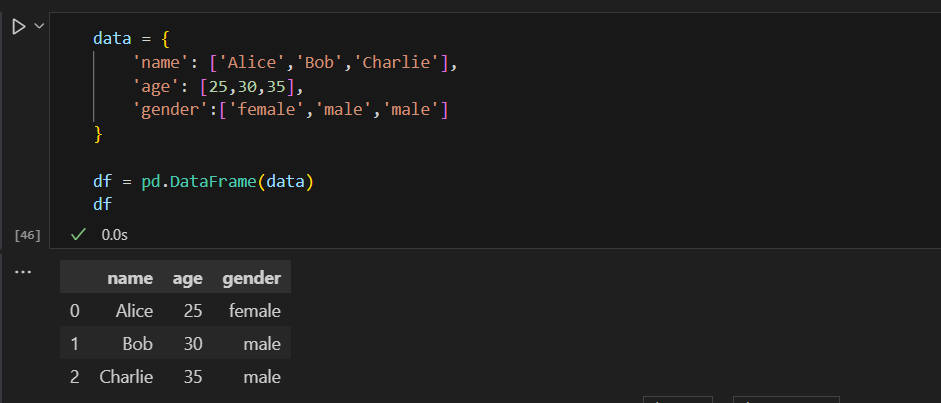
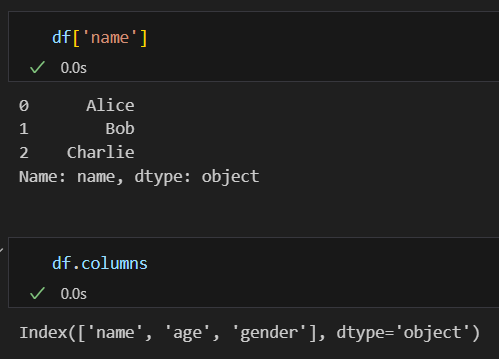
dataset[칼럼명]
인덱스와 함께 목록형으로 칼럼명을 확인할 수 있습니다.
.columns
리스트 형태로 칼럼명 출력, 변수로 설정해서 리스트에 새로운 칼럼명을 넣어 이름을 재지정 할 수 있습니다.
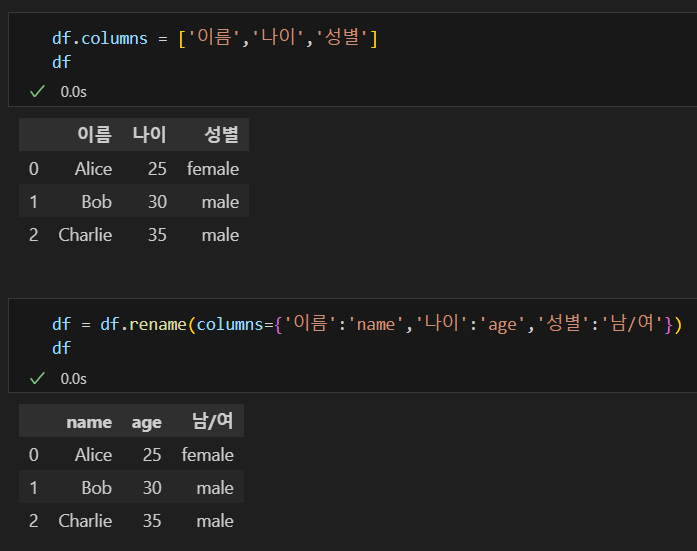
.rename(columns = {'before' : 'after'})
before 에 구 칼럼명, after에 신 칼럼명을 넣어 칼럼명을 바꿀 수 있습니다.
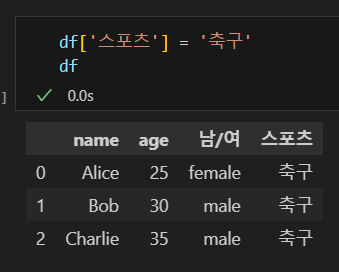
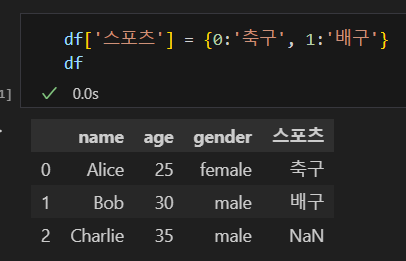
dataset[칼럼명] = 값
새로운 칼럼을 추가할 수 있습니다. 칼럼을 추가하고 인덱스별로 값을 다르게 할 경우 값을 딕셔너리 형태로 인덱스와 매칭 해서 넣어줍니다.
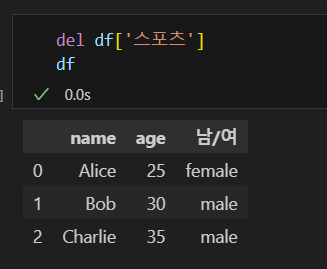
del dataset[칼럼명]
칼럼을 삭제할 수 있습니다.
지금까지 pandas 를 활용한 데이터셋 불러오기/저장하기, 인덱스, 칼럼을 알아봤습니다.
다음 포스트에서 이어서 보겠습니다.
오랑우탄이 영어를 하고 오랑이가 코드마스터가 되는 그날까지~
'PYTHON > 데이터분석' 카테고리의 다른 글
| 데이터 전처리 & 시각화 (7) Matplotlib 개념 익히기 (2) | 2024.07.18 |
|---|---|
| 데이터 전처리 & 시각화 (6) 데이터 시각화란? (0) | 2024.07.18 |
| 데이터 전처리 & 시각화 (5) Pandas 개념 익히기 3 (0) | 2024.07.18 |
| 데이터 전처리 & 시각화 (4) Pandas 개념 익히기 2 (0) | 2024.07.17 |
| 데이터 전처리 & 시각화 (1) 데이터 전처리란? (0) | 2024.07.17 |



