오랑우탄의 반란
[Pandas] value_counts 완전분석 (활용 포함) 본문
pandas 에서 자주 사용되는 value_counts() 함수에 대해 알아보겠습니다.
Parameters
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
Series.value_counts()
normalize: 값의 상대적 빈도로 표시
sort: count 정렬 여부
ascending: 내름차순으로 count 정렬
bins: 연속형 자료를 이산 가격으로 bin
dropna: NaN 값 미포함 여부
우선 연습을 위한 데이터프레임을 생성해줍니다.
data = pd.DataFrame({
'Name':['Alice','Bob','Charlie','Rachel','James','Pedro','Emma','Ana'],
'Score': [60, 80, 100, 70, 80, 70, 70, 100],
'Grade': ['D','B','A',np.nan, 'B', 'C', 'C', np.nan]
})
value_counts 함수는 기본적으로 Series 즉 하나의 칼럼에 각 항목별 개수를 확인할 때 사용합니다.
특히 value_counts 만 쓰기보다는 앞에 groupby 조건을 달아서 사용하기에 유용했습니다.
Dataframe에 사용도 가능하지만 웬만해서는 중복값이 안 들어가 있을 거기 때문에 모두 1로 출력이 되어 크게 의미가 없겠지요?
그럼 바로 가장 기본적인 출력 결과부터 봅시다.
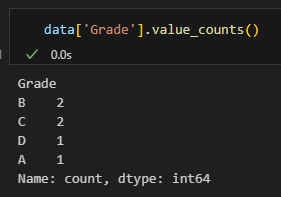
각 grade 별로 몇 개의 값이 있는지 세어줍니다.
sort=True
아래 결과에서 볼 수 있듯이 파라미터가 기본적으로 내림차순 정렬로 보이게 설정되어 있습니다.
이를 False 로 바꾸면 무작위의 결과물이 나오지만 사실상 이렇게 쓸 일은 없을거라 참고만 하면 될 듯 합니다.
data['Grade'].value_counts()

ascending=False
마찬가지로 기본적으로 내림차순으로 보기 때문에 ascending=True 도 참고만 해주시면 되겠습니다.
count가 적은 것을 위주로 보려고 하는 경우이면 유용할 수도 있겠네요.
자연스럽게 Grade 또한 이 정렬 기준에 따른다는 것을 볼 수 있습니다.


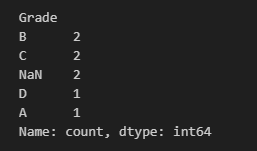
dropna=True
value_counts 함수는 기본적으로 NaN 값을 세지 않습니다.
만약 결측치의 개수도 파악하고 싶다면 dropna=False로 설정해주시면 됩니다.

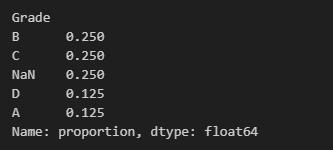
normalize=False
value_counts 함수로는 보통 정수 단위의 개수를 파악하기 때문에 이 파라미터를 많이 사용하지는 않을 것 같은데요,
시각화 없이 간단하게 각 값 별 비율을 파악하려고 할 때 유용하게 쓰일 듯 합니다.
지금은 데이터가 적고 개수도 작지만 특히 큰 데이터에서는 한 눈에 파악하기 좋겠습니다.
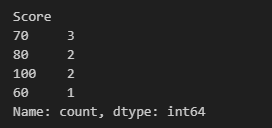
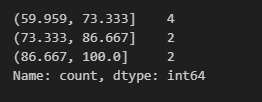
bins=None
bins 파라미터는 숫자형 데이터에 대해서만 사용이 가능합니다.
score 칼럼에 대해 적용을 해보면 아래와 같이 3개의 구간으로 전체 점수가 나뉜 것을 확인할 수 있습니다.
큰 데이터에 대해 구간별로 분포도를 간단하게 확인할 때 유용하겠습니다.
value_counts 활용
이제 value_counts 함수에 대한 활용 예시를 살펴보겠습니다.
데이터 개수와 분포를 간단하게 확인하기에 최적인 함수지요.
groupby, sort_index, to_frame
앞서 count 값에 대해 정렬하는 것을 다뤘는데요, 실제 개수를 세는 칼럼을 기준으로 정렬하고 싶은 경우도 많이 있습니다.
이때는 sort_index 를 붙여줘서 사용하면 됩니다.

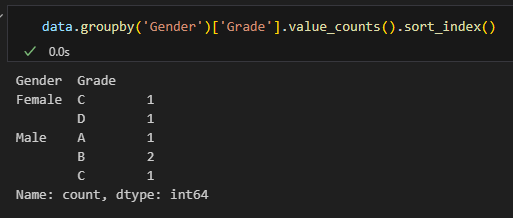
더 나아가 만약 성별을 기준으로 grade 를 보고 싶은 경우, groupby 로 묶어준 뒤에 붙여서 사용해주면 됩니다.
마찬가지로 sort_index 를 사용해 각 성별에 대해 grade 오름차순으로 개수를 확인할 수 있지요.
만약 데이터프레임 형식으로 보고싶다면 to_frame 을 사용해주면 됩니다.

loc[lambda x]
마지막으로 특정 개수만 보고 싶은 경우 위치를 찾아주는 loc 함수로 조건을 달아서 해당하는 값만 조회할 수 있습니다.
예를 들어 grade 별 개수가 2 이상인 값만 보고싶은 경우, lambda 함수로 x보다 크거나 같다 라는 조건을 걸어줍니다.

오랑우탄이 영어를 하고 오랑이가 코드마스터가 되는 그날까지~
'PYTHON > 데이터분석' 카테고리의 다른 글
| 한 눈에 보는 데이터 인프라 (ETL, 웨어하우스, 레이크, 마트) (2) | 2024.09.04 |
|---|---|
| [기초통계] 가설검정의 주의점 (파이썬) (0) | 2024.08.02 |
| [기초통계] 상관관계 (파이썬) (0) | 2024.08.02 |
| [기초통계] 회귀 (파이썬) (0) | 2024.08.02 |
| [기초통계] 유의성검정 (파이썬) (2) | 2024.08.01 |



