오랑우탄의 반란
[Pandas] Pivot Table 피벗테이블 완전분석 (실습 포함) 본문
피벗 테이블에 대해 알아보겠습니다.
Parameters
import pandas as pd
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=_NoDefault.no_default, sort=True)
pd.pivot_table()
data: 데이터프레임 오브젝트
values: 데이터프레임의 특정 칼럼명 (복수 가능)
* index 행(인덱스)에 들어가는 항목, group by 개념
* columns 열에 들어가는 항목, group by 개념
* aggfunc 값에 적용되는 집계 함수
fill_value 결측치 Na/공백 대신 들어갈 값
margins 총계 (누적합) 추가
dropna 결측치 포함 여부
margins_name 총계 행열명
observed 관측 가능한 값만 포함 여부
sort index/column 기준으로 정렬
Data, Values
우선 연습을 위한 데이터프레임을 생성해줍니다.
df = pd.DataFrame({
'Date': ['2023-01-01','2023-01-01','2023-01-02','2023-01-02','2023-01-01',],
'Category': ['A','B','A','B','A'],
'Value': [10,20,30,40,50]
})| Date | Category | Value | |
| 0 | 2023-01-01 | A | 10 |
| 1 | 2023-01-01 | B | 20 |
| 2 | 2023-01-02 | A | 30 |
| 3 | 2023-01-02 | B | 40 |
| 4 | 2023-01-01 | A | 50 |
해당 데이터로 간단하게 피벗테이블을 만들어봅니다.
이때 두 가지 방법으로 설정할 수 있는데요, 하나씩 살펴봅시다.
1. pd.pivot_table()
정석적인 작성법으로 pd.pivot_table() 함수를 사용해서 data, values, index, columns, aggfunc 를 넣어줍니다.
ptable1 = pd.pivot_table(df, values='Value', index = 'Date', columns = 'Category', aggfunc='sum')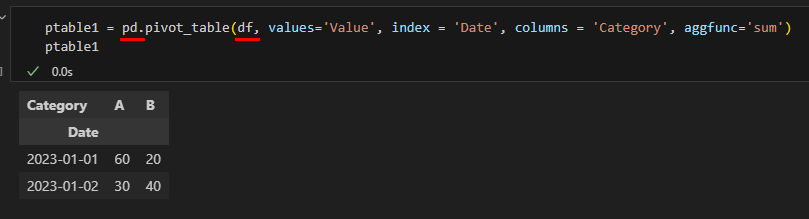
2. 데이터프레임.pivot_table()
pd 대신 데이터 자체에 pivot_table() 함수를 적용해서 values, index, columns, aggfunc 만으로 적용 가능합니다.
ptable2 = df.pivot_table(values='Value', index = 'Date', columns = 'Category', aggfunc='sum')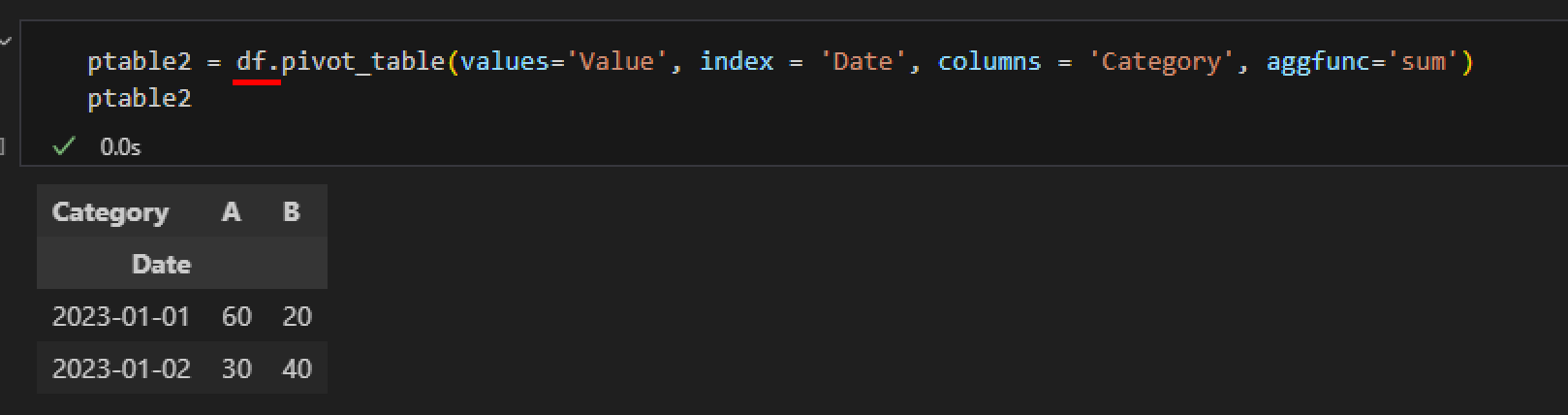
결과는 동일하게 나와서 편한대로 사용하면 되겠습니다.
Index, Columns
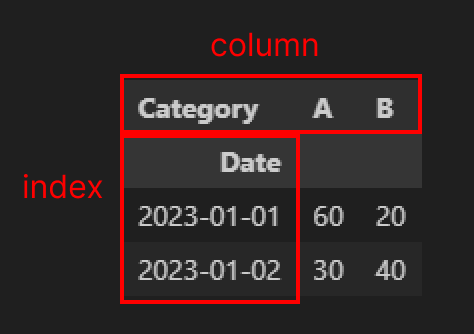
index, column 은 간단합니다.
함수 설정 시 각 인덱스, 칼럼에 들어갈 원본 데이터프레임의 칼럼명을 넣으면 됩니다.
index, column 은 여러 개의 칼럼명을 받을 수 있으며, 이런 경우 대괄호로 묶어주면 됩니다. 위에서 본 데이터에 subcategory 칼럼을 추가해서 해보겠습니다.
df = pd.DataFrame({
'Date': ['2023-01-01','2023-01-01','2023-01-02','2023-01-02','2023-01-01',],
'Category': ['A','B','A','B','A'],
'Subcategory':['X','X','Y','Y','X'],
'Value': [10,20,30,40,50]
})| Date | Category | Subcategory | Value | |
| 0 | 2023-01-01 | A | X | 10 |
| 1 | 2023-01-01 | B | X | 20 |
| 2 | 2023-01-02 | A | Y | 30 |
| 3 | 2023-01-02 | B | Y | 40 |
| 4 | 2023-01-01 | A | X | 50 |
pivot = df.pivot_table(index = 'Date', columns = ['Category','Subcategory'],values = 'Value', aggfunc='sum')
Aggfunc
| sum | 합 | first | na 제외 첫번째 값 |
| mean | 평균 | last | na 제외 마지막 값 |
| min | 최솟값 | median | 중앙값 |
| max | 최댓값 | prod | 곱 |
| count | 중복값 포함 세기 | var | 분산 |
| nunique | 중복값 한 번만 세기 | std | 표준편차 |
Fill_value, dropna
각각 Na 값에 대한 처리를 해주는 파라미터로, fill_value 는 na나 공백을 특정 값으로 채워주고, dropna 는 피벗 생성 이전에 Na 데이터를 우선 제외해주는 역할입니다.
기존에 Na 였던 부분이 0으로 채워진 것을 확인할 수 있습니다.

Margins, margins_name
각 열과 행에 대한 총계를 구해주는 파라미터로, margins=True 로 설정한 후 margins_name 으로 행/열 명을 변경할 수 있습니다.
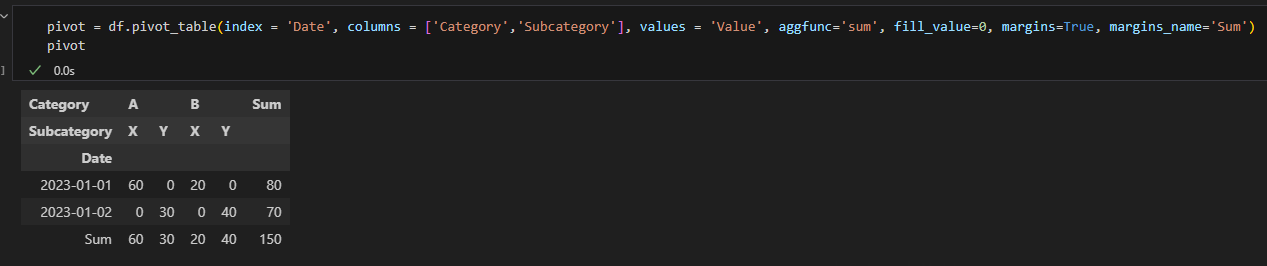
Observed, sort
둘 다 default = True 로 설정되어 있고 잘 쓰이지 않는 파라미터입니다.
sort=False 로 설정하는 경우 테이블 내에서 자동으로 정렬 및 group 된 것이 풀리면서 개별 값으로 반환됩니다.
값에 대한 정렬이 필요한 경우 sort_values 를 사용합시다.
pivot table 실습
개념으로만 봐서는 와닿지 않기 때문에 오랑이와 함께 직접 실습 데이터로 살펴봅시다.
소상공인시장진흥공단 제공 소상공인시장진흥공단_상가(상권)정보_20240331 中 서울지역 5,000개의 가게 정보를 갖고 연습해보겠습니다. (원본 데이터 바로가기)
서울시내 상가들을 업종별, 구별로 비교해 볼 수 있는 피벗테이블을 만들어봅시다.
기준이 될 칼럼은 상가의 업종 대분류 데이터를 담은 '상권업종대분류명'과 서울특별시 내 행정구 데이터를 담운 '시군구명' 두 개입니다.
우선 원본 데이터를 봅시다.

우선 가장 기본적인 틀로 피벗테이블을 뽑아봅니다.
상권업종대분류명을 index로, 시군구명을 column 으로, 그리고 상가업소번호를 count 한 값을 value 로 넣어줍니다.
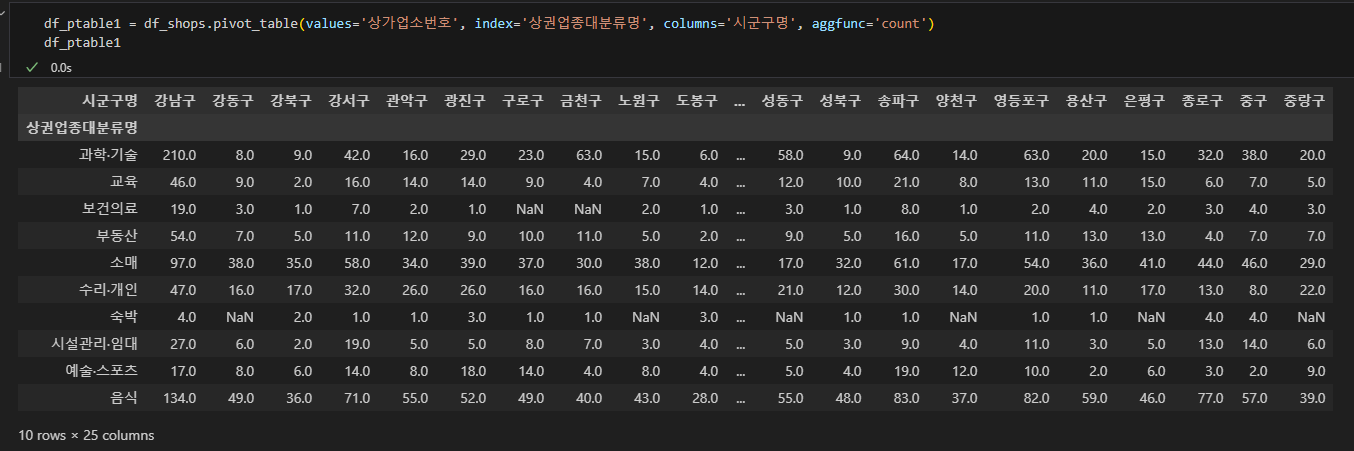
하지만 테이블을 보면 NaN 결측치가 포함된 것을 볼 수 있습니다.
이를 모두 0으로 만들어주고 총계도 함께 구해봅시다.
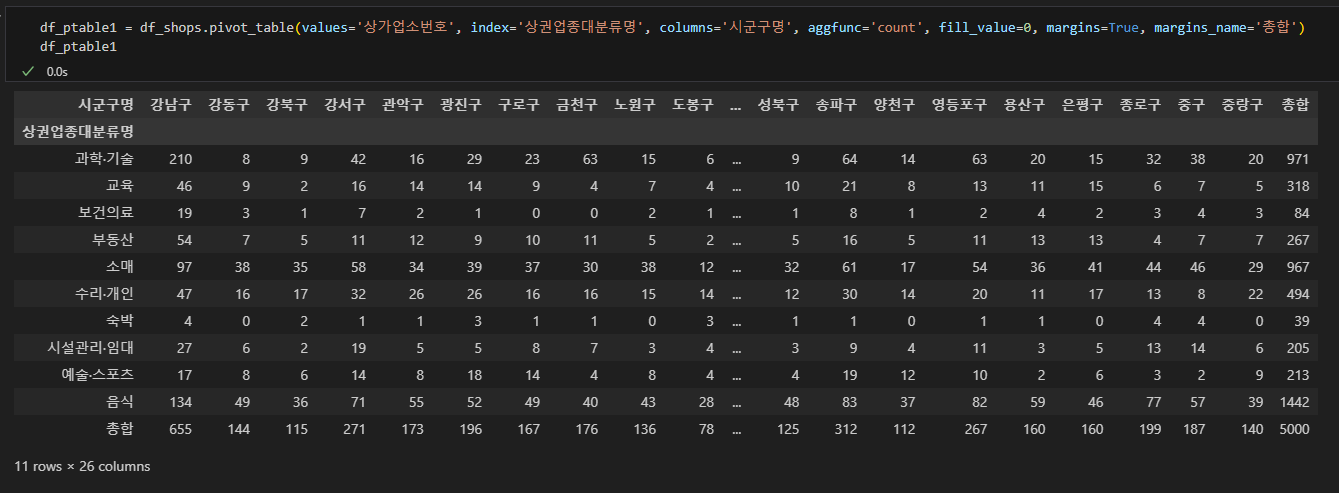
최종 출력 함수 자체는 아주 간단합니다.
앞서 배운 파라미터를 하나씩 모두 적용하면 아래와 같이 나옵니다.
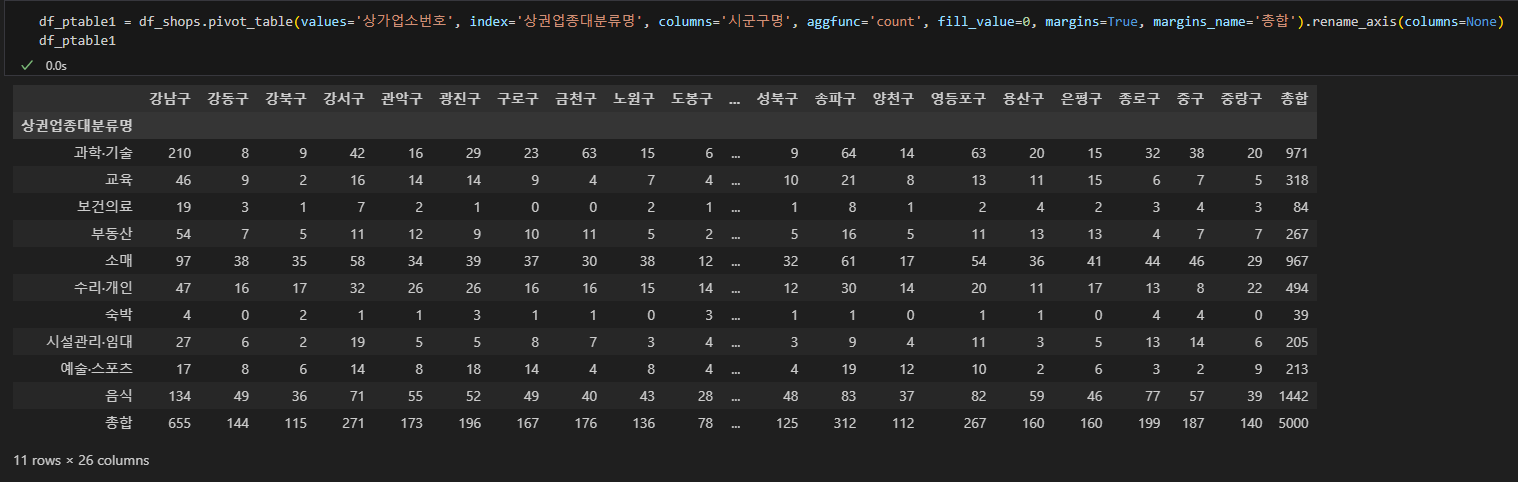
df_ptable1 = df_shops.pivot_table(values='상가업소번호', index='상권업종대분류명', columns='시군구명',
aggfunc='count', fill_value=0, margins=True, margins_name='총합').rename_axis(index=None)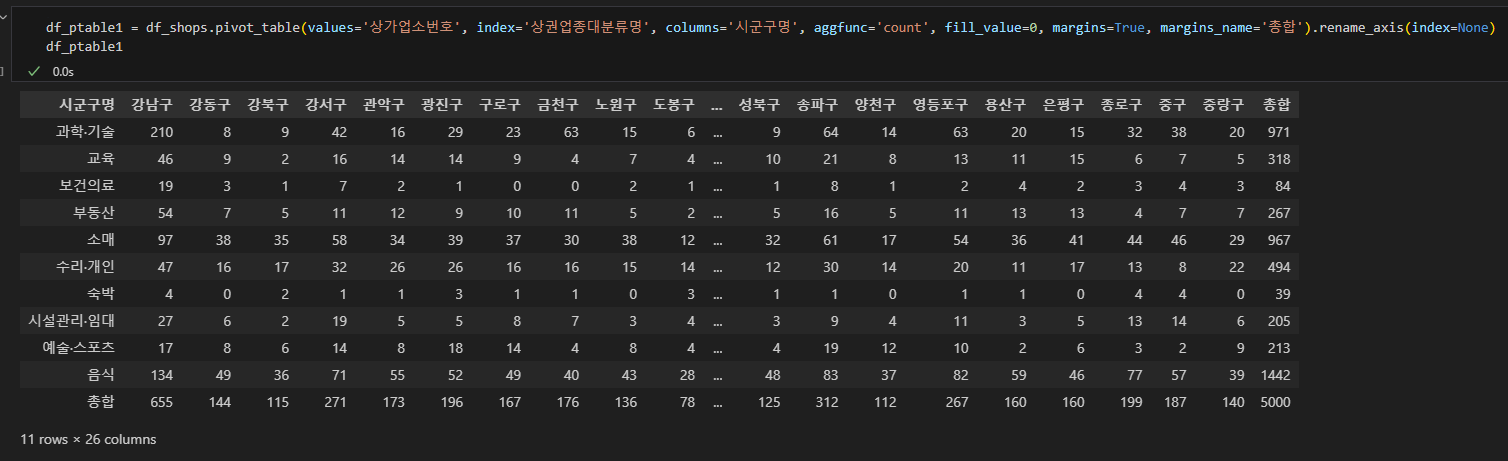
이때 인덱스 상단에 멀티인덱스로 들어간 '상권업종대분류명'이 거슬리는데 이거를 제거해주는 함수가 rename_axis(index=None)입니다.
rename_axis(index/columns = None)
위의 예시처럼 index=None 으로 파라미터를 설정하면 행 칼럼의 멀티인덱스명이 삭제되고, 반대로 columns=None 으로 설정하면 열들의 멀티인덱스명인 '시군구명' 이 삭제되어 아래처럼 출력됩니다.
여기서 만약 '상가업소번호' 칼럼을 사용하지 못할 경우 어떻게 풀어야 할까요?
(사실 오랑이는 '상권업종대분류명', '시군구명' 두 개의 칼럼만 사용해야 하는 줄 알고 돌아서 어렵게 풀었답니다..)
코딩의 매력.. 어떻게든 방법은 있다는 점입니다 ^^
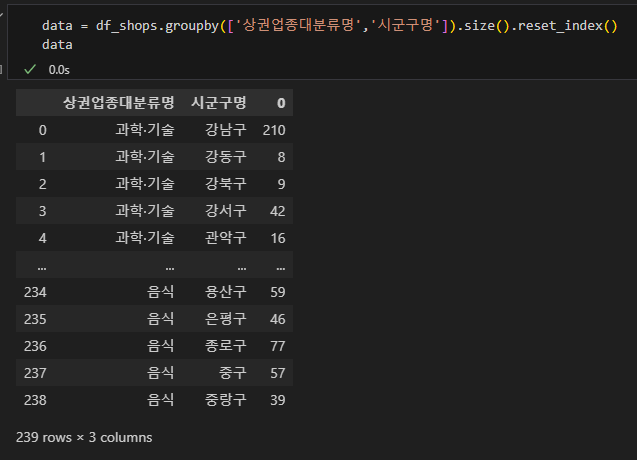
우선 각 칼럼을 기준으로 그룹화했을 때 각 그룹별 행의 개수를 구해주는 .groupby().size() 함수를 사용해 데이터프레임을 만들어줍니다. 여기서 사실상 완성입니다.
칼럼명이 저렇게 '0' 인 경우 프로그램이 인식을 잘 하지 못하므로 '합계'로 칼럼명까지 지정해줍니다.
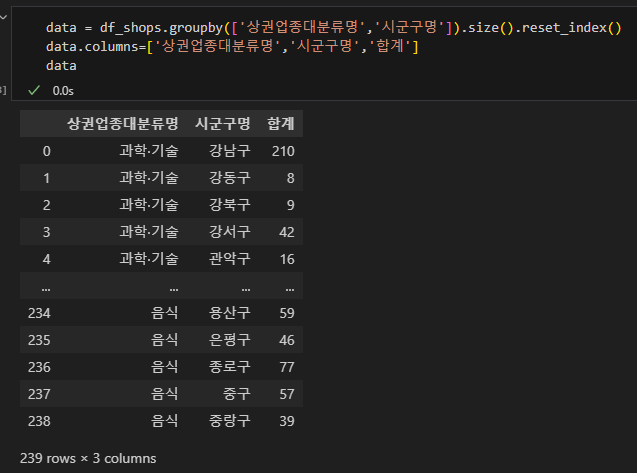
이 데이터프레임을 기반으로 피벗테이블을 생성해주면 위에 예시와 동일하게 출력됩니다.
이때 주의해야 할 점은 aggfunc='count' 이 아닌 aggfunc='sum' 을 사용해야 한다는 것 (전자로 작성하면 합계 칼럼에 대한 모든 값이 개별 값으로 간주돼 피벗테이블의 모든 칸이 1로 출력됩니다.)

이렇게 피벗테이블에 관해 간단히 살펴봤습니다.
오랑우탄이 영어를 하고 오랑이가 코드마스터가 되는 그날까지~
'PYTHON > 데이터분석' 카테고리의 다른 글
| [기초통계] 데이터 분포 시각화 (파이썬) (0) | 2024.08.01 |
|---|---|
| [기초통계] 통계 기초 개념 시각화 (파이썬) (0) | 2024.08.01 |
| 데이터 전처리 & 시각화 (7) Matplotlib 개념 익히기 (2) | 2024.07.18 |
| 데이터 전처리 & 시각화 (6) 데이터 시각화란? (0) | 2024.07.18 |
| 데이터 전처리 & 시각화 (5) Pandas 개념 익히기 3 (0) | 2024.07.18 |



