오랑우탄의 반란
[기초통계] 통계 기초 개념 시각화 (파이썬) 본문
오늘 오랑이는 통계학의 기초 개념과 이를 시각화해주는 파이썬 코드를 살펴볼 예정입니다.
대학교때 필수교양으로 통입을 들었었는데 그게 벌써 4어년 전이니.. 기억이 날 리가

새로 배운다는 마음으로 임해봅니다 ^^
기술통계 vs 추론통계
| 기술통계 descriptive statistics |
추론통계 inferential statistics |
|
| 개념 | 정량 데이터를 특정 대표값으로 요약하는 것 | 표본 데이터로 모집단의 특징을 파악하고 가설검증하는 것 |
| 요소 | 평균, 중앙값, 분산, 표준편차, 범위, 최빈값 등 | 신뢰구간(0.95) 가설검증(p-value로 귀무가설 H0 기각, 대립가설 H1 유지) |
| 사용예시 | 회사 매출 데이터 요약 | 고객 만족도 설문 결과 분석 |
기술통계의 개념들을 파이썬 라이브러리로 시각화 해봅시다.
우선 기본적으로 사용할 데이터분석, 계산, 시각화 라이브러리를 불러와주고 사용할 샘플 데이터를 설정해줍니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = [85, 90, 78, 92, 88, 76, 95, 89, 84, 91]
데이터 위치 및 변이 추정
numpy 의 여러 함수를 쓰면 간단한 계산이 가능합니다.
# 위치 추정
mean = np.mean(data)
median = np.median(data)
# 변이 추정
variance = np.var(data)
std_dev = np.std(data).round(2)
data_range = np.max(data) - np.min(data)
print(f'평균: {mean}, 중앙값:{median}, 분산: {variance}, 표준편차: {std_dev}, 범위: {data_range}')
위치 추정 예시: 학생들의 시험 점수에서 평균 점수, 중간 점수를 계산
범위 추정 예시: 매출 데이터의 변이를 분석하여 비즈니스의 안정성을 평가
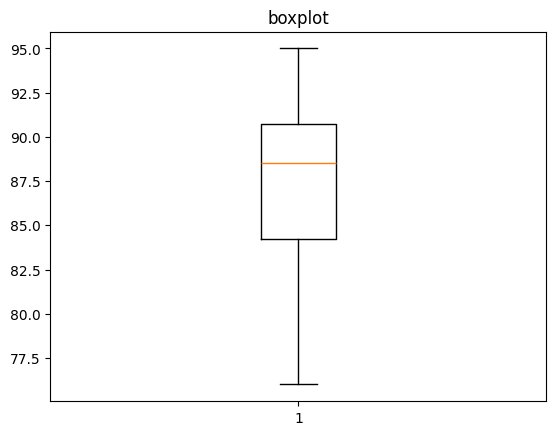
데이터 분포 확인
위에서 구한 수치에 대해 히스토그램과 박스플롯으로 데이터의 분포를 시각화할 수 있습니다.
# 히스토그램
plt.hist(data, bins=5)
plt.title('histogram')
plt.show()
# 박스플롯
plt.boxplot(data)
plt.title('boxplot')
plt.show()
이진/범주 데이터 탐색
최빈값으로 데이터의 빈도를 확인할 수 있습니다.
ex) 고객 만족도 설문에서 만족/불만족의 빈도 분석
satisfaction = ['satisfaction', 'satisfaction', 'dissatisfaction',
'satisfaction', 'dissatisfaction', 'satisfaction', 'satisfaction',
'dissatisfaction', 'satisfaction', 'dissatisfaction']
satisfaction_counts = pd.Series(satisfaction).value_counts()
satisfaction_counts.plot(kind='bar')
plt.title('satisfaction distribution')
plt.show()

상관관계
두 변수 사이 상관관계를 파악할 수 있습니다. 절대값이 1에 가까울수록 높은 상관도를 보이는 것이고,
절대값 0.5까지는 중간 정도의 상관관계가, 0.4까지는 낮은 상관관계가 있다고 봅니다.
ex) 공부 시간과 시험 점수 간의 상관관계를 분석
study_hours = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
exam_scores = [95, 90, 85, 80, 75, 70, 65, 60, 55, 50]
correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
print(f"공부 시간과 시험 점수 간의 상관계수: {correlation}")
plt.scatter(study_hours, exam_scores)
plt.show()
이때 상관관계 함수 뒤에 [0, 1] 슬라이싱이 붙은 이유는 뭘까요?
correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
결과가 리스트 2개로 구성된 arrary 로 출력되기 때문입니다.
대각선으로는 자기 자신에 대해 1의 상관관계를 보이고, 양옆 위가 두 변수 사이의 상관관계이며 두 값 또한 동일합니다.
그렇기 때문에 둘 중 하나의 값만 출력해줘도 되는 것이기에 [0, 1]
즉 위치 0의 리스트의 위치 1의 값을 출력해주는 것입니다.

다중 변수 상관관계 탐색
아마 가장 많이 쓰이는 분석법이지 않을까 싶습니다.
변수가 여럿일 때의 상관관계를 시각화하는 방법이지요.
ex) 여러 마케팅 채널의 광고비와 매출 간의 관계 분석
data = {'TV': [230.1, 44.5, 17.2, 151.5, 180.8],
'Radio': [37.8, 39.3, 45.9, 41.3, 10.8],
'Newspaper': [69.2, 45.1, 69.3, 58.5, 58.4],
'Sales': [22.1, 10.4, 9.3, 18.5, 12.9]}
df = pd.DataFrame(data)
print(df)
print(df.corr())
데이터를 데이터프레임으로 변환해준 후, 각 변수 간 상관관계를 corr 로 뽑아봅니다.


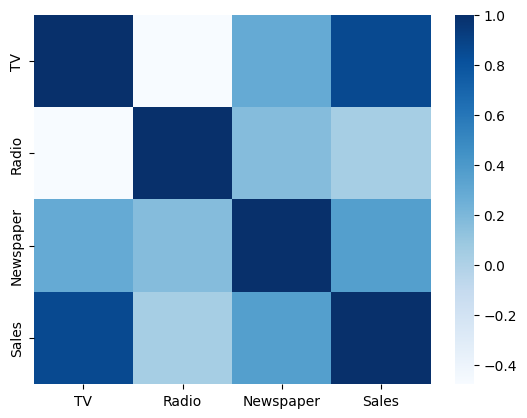
숫자만으로는 눈에 잘 들어오지 않을 수 있으니 모든 값에 대해 산점도, 히트맵으로 시각화를 해줍니다.
# 산점도 모음
sns.pairplot(df)
plt.show()
# 히트맵
sns.heatmap(df.corr(), cmap="Blues")
지금까지 통계의 정말 기초 중의 기초를 살펴봤습니다.
다음 포스트에서는 각종 분포를 다루겠습니다.
오랑우탄이 영어를 하고 오랑이가 데이터분석가가 되는 그날까지~
'PYTHON > 데이터분석' 카테고리의 다른 글
| [기초통계] 유의성검정 (파이썬) (2) | 2024.08.01 |
|---|---|
| [기초통계] 데이터 분포 시각화 (파이썬) (0) | 2024.08.01 |
| [Pandas] Pivot Table 피벗테이블 완전분석 (실습 포함) (0) | 2024.07.23 |
| 데이터 전처리 & 시각화 (7) Matplotlib 개념 익히기 (2) | 2024.07.18 |
| 데이터 전처리 & 시각화 (6) 데이터 시각화란? (0) | 2024.07.18 |



