오랑우탄의 반란
[ML] 머신러닝 선형회귀분석 파이썬 실습 (VSCode) 본문
머신러닝 선형회귀분석 실습
회귀분석은 scikit-learn 라이브러리에서 제공해주는 함수만 다룰 줄 알면 매우 간단한데요,
아래 단계에 따라 진행하겠습니다.
- 사용할 라이브러리 설치
- 데이터 확인 (Seaborn tips)
- 선형회귀 모델 훈련
- 모델 평가
1. 라이브러리 설치
우선 사용할 라이브러리를 모두 import 해줍니다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import sklearn #scikit-learn으로 적으면 안됨
라이브러리 설치가 안 되어 있다면 pip 설치를 진행해주세요.
! pip install 라이브러리
2. 데이터 확인
이번 실습에서 사용할 데이터는 Seaborn 라이브러리에 기본 내장된 tips 데이터로, 아래와 같은 구성입니다.
tips_df = sns.load_dataset('tips')
tips_df.head()
해당 데이터에 대해 total_bill (X) 을 알면 얼마의 tip (Y) 을 받을 수 있을지 예측하고자 회귀분석을 진행합니다.
모델을 훈련하기에 앞서, 두 칼럼의 상관관계와 분포를 산점도로 먼저 확인해줍니다.
선형으로 양의 상관관계를 가진 것을 확인했으니, 선형 회귀 분석을 진행해도 좋겠습니다.
sns.scatterplot(data = tips_df, x='total_bill', y='tip')
3. 선형회귀 모델 훈련
본격적인 모델 훈련에 앞서 자주 쓰이는 함수를 짚고 넘어가겠습니다.
| Class: sklearn.linear_model.LinearRegression | |
| fit | 데이터 학습 |
| coef_ | 회귀 계수 (w1) |
| intercept_ | 편향 bias (w0) |
| predict | 데이터 예측 |
앞서 scikit-learn 라이브러리를 import 했는데요, 그 중 linear_model의 LinearRegression 클래스를 사용할 예정입니다.
해당 클래스를 import 해서 변수에 저장해두고 이번 실습의 분석 모델로 사용하겠습니다.
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
훈련할 모델에 넣어줄 데이터 또한 변수에 넣어주고, fit 함수를 사용해 훈련을 진행하면 아래와 같이 뜹니다.
X = tips_df[['total_bill']]
y = tips_df[['tip']]
model_lr2.fit(X=X, y=y)
모델을 훈련시킬 데이터에 왜 대괄호가 추가되나요?
☞ 모델 훈련 시 DataFrame 형태의 데이터를 넣어줘야 하기 때문에 기존의 칼럼 그대로 Series 형태의 데이터로 코드를 실행하면 아래와 같은 에러가 발생합니다.
ValueError: Expected a 2-dimensional container but got <class 'pandas.core.series.Series'> instead.
Pass a DataFrame containing a single row (i.e. single sample) or a single column (i.e. single feature) instead.

Series vs DataFrame


선형회귀 이론 포스트에서 언급했던 선형회귀 수식을 사용할 건데요
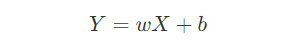
Y = w1X + w0 형식으로 문자만 조금 바꿔서 사용하겠습니다. (w1: 가중치, w0: 편향/bias )
가중치를 구하는 함수 coef_ 와 편향을 구하는 함수 intercept_ 를 사용해 수식을 만들어줍니다.
이때 가중치는 대괄호 2개에 들어가있는 형태로 출력되기 때문에 두 번 슬라이싱 해줍니다.
w1 = model_lr2.coef_[0][0]
w0 = model_lr2.intercept_[0]
print(f'y = {w1:.2f}x + {w0:.2f}')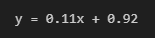
이때 나온 결과는 어떻게 해석할 수 있을까요?
전체 금액이 $1 오를 때마다 팁이 $0.11 추가된다
혹은 전체 금액이 $100 오르면 팁이 $11 추가된다고 할 수 있겠습니다.
이 관계를 바탕으로 예측 데이터를 predict 함수로 생성해줍니다.
실제 데이터의 경우 tips_df 의 tip 칼럼이 되겠지요?
y_true = tips_df['tip']
y_pred = model_lr.predict(tips_df[['total_bill']])
이때 만든 예측 데이터를 tips_df 에 칼럼으로 추가해준 후 앞서 그렸던 산점도에 직선으로 시각화할 수 있습니다.
tips_df['pred'] = y_pred_tips
sns.lineplot(data = tips_df, x='total_bill', y='pred', color='red')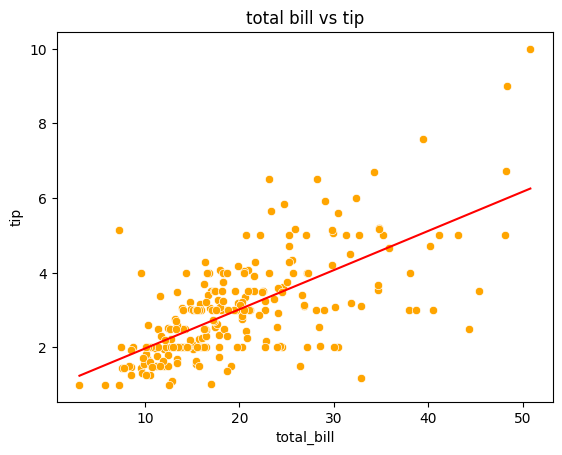
4. 선형회귀 모델 평가
metrics 에서 mse와 rscore 값을 구해줄 함수를 import 해서 실제 데이터와 예측 데이터를 넣어서 모델 평가를 진행합니다.
from sklearn.metrics import mean_squared_error, r2_score
print(mean_squared_error(y_true,y_pred_))
print(r2_score(y_true,y_pred))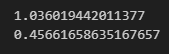
해당 모델의 MSE 가 1 이 나왔지만, y값 total_bill 과 tips의 단위가 다르기 때문에 성급하게 좋다고 하기는 어렵습니다.
r score 의 경우 분야마다 기준이 다른데요, 사회/문화/경제 분야에서는 40이면 좋다고 평가된다고 합니다.
여기서는 너무 낮게 나온 걸 볼 수 있는데요, total_bill 대신 다른 칼럼들에 대해 변수 추가를 해서 다중선형회귀로 다시 분석해봐야 합니다.
다음 포스트에서 다중선형회귀의 기초 이론 그리고 같은 데이터로 다시 실습을 진행해보겠습니다.
'PYTHON > 머신러닝' 카테고리의 다른 글
| [ML] (다중)로지스틱회귀 분류 분석 파이썬 실습 (VSCode) (0) | 2024.08.12 |
|---|---|
| [ML] 로지스틱회귀 기초 이론 및 수식 정리 (분류 분석) (0) | 2024.08.09 |
| [ML] 머신러닝 다중선형회귀분석 파이썬 실습 (VSCode) (0) | 2024.08.09 |
| [ML] 선형회귀 기초 이론 및 수식 정리 (회귀 분석) (0) | 2024.08.08 |
| [ML] 머신러닝이란? (0) | 2024.08.08 |



